
The Pattern Holds
We replicated our Marcus Aurelius findings at a new layer, then tested the whole method on 12 commercial ad copy styles trained into a single LoRA.


In the first two parts of this series, we reported two findings about what happens inside a language model fine-tuned on Marcus Aurelius using LoRA.
First: the individually interpretable features that a sparse autoencoder finds inside the LoRA aren’t what’s doing most of the work, though this is to some extent layer-dependent. Most LoRA-specific features were causally inert. The real adaptation lived in a distributed reweighting of shared features, features used by both the base model and the fine-tuned model, but at different intensities.
Second: those shared features aren’t random. They organize into co-activation clusters with clear thematic identities, measurable causal impact, and two distinct encoding regimes: tight circuits for narrow themes, loose coalitions for broad philosophical reasoning.
The first finding was demonstrated at both layers in the first newsletter, though the clustering analysis in the second was reported only at Layer 22. The obvious question was whether any of it would hold up when we changed the conditions more broadly. This piece reports on two tests. We changed the layer. Then we changed the domain entirely. The short version: the pattern holds in both cases, and the new domain reveals organizational structure we couldn’t have seen with Marcus alone.
A Different Layer
The co-activation analysis in the second newsletter was reported at Layer 22 of a 28-layer model. But the SAE analysis has been running at both layers from the start. In the first newsletter, we reported cross-reconstruction gaps at both Layer 16 and Layer 22 (both around 5×), and the crosscoder at Layer 16 showed the same asymmetry: 6 LoRA-specific features against 60 base-specific, the same “more suppressed than created” pattern we found at Layer 22. What we hadn’t done was the clustering. The question: does the co-activation structure that appeared at Layer 22 also appear at Layer 16, or was it specific to the model’s late layers?
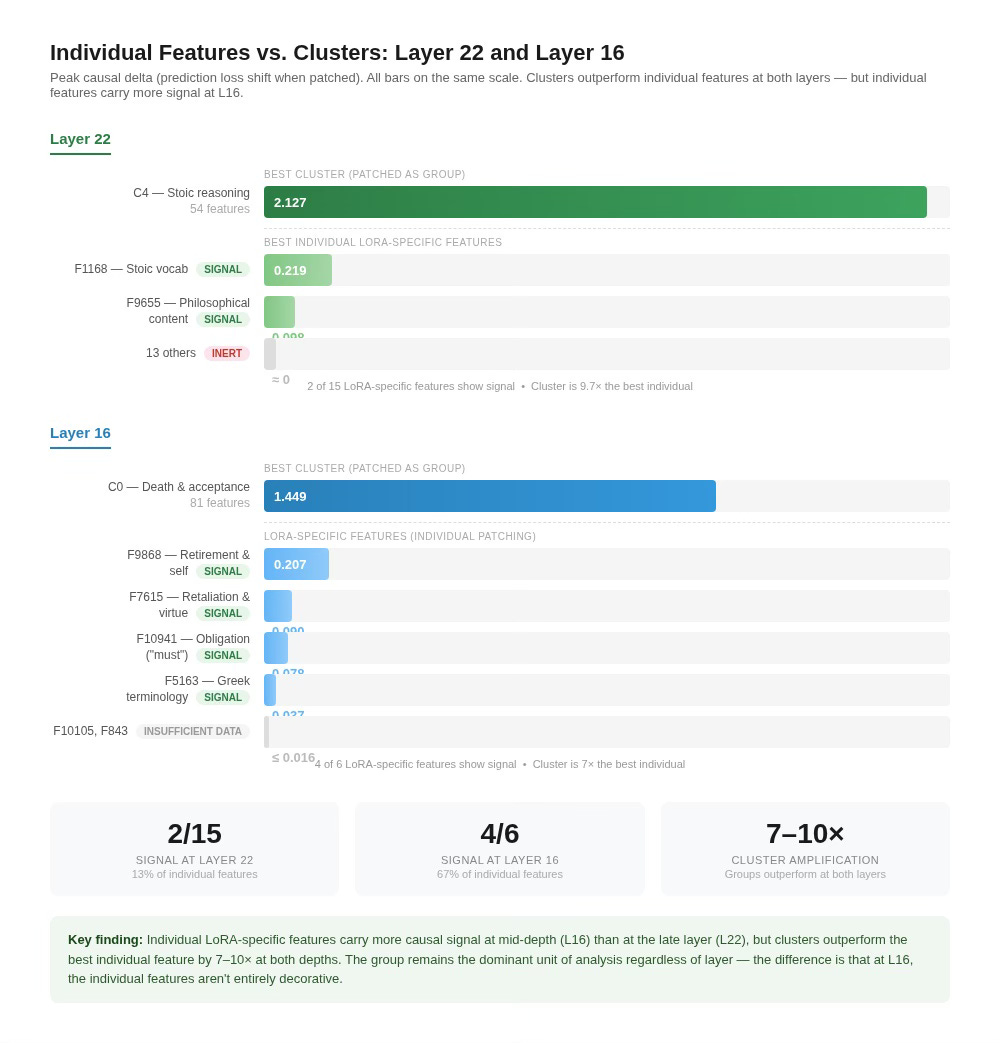
We ran identical clustering on the Layer 16 shared features: 211 shared features across 779 evaluation chunks, k-means with k = 5, the same procedure as before. The silhouette score (0.098) is slightly lower than L22’s (0.119) and low by conventional clustering standards, consistent with mid-layer representations being less cleanly separable, but the clusters it recovers are thematically coherent, as the descriptions below show.
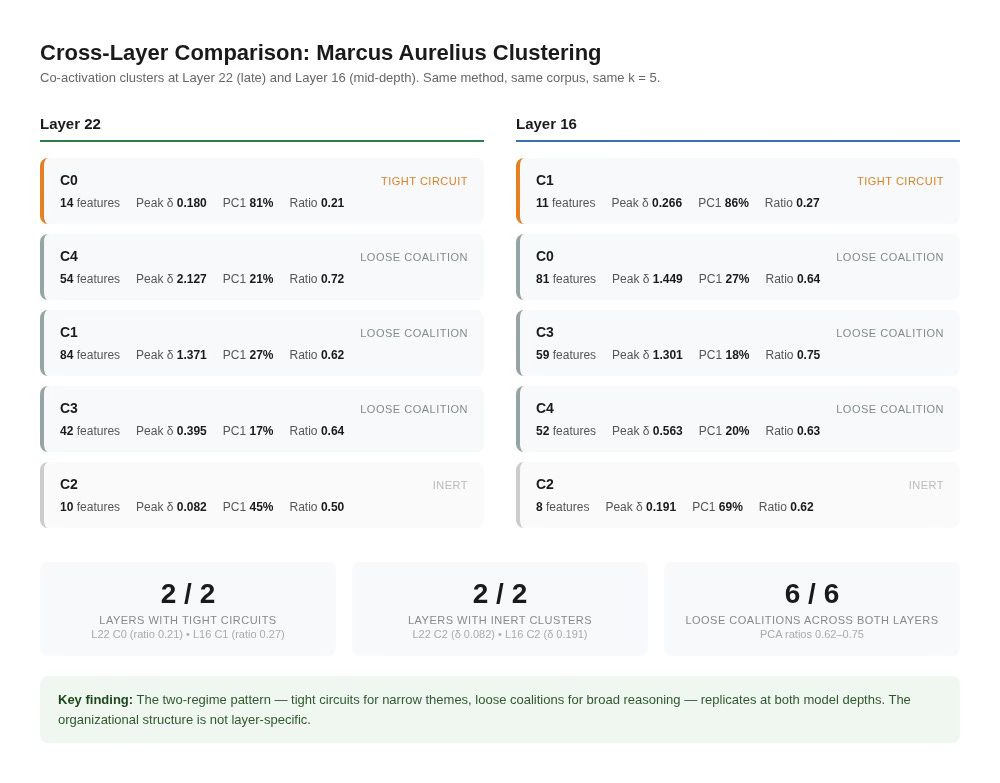
The two-regime pattern replicates. At Layer 16, Cluster 1 is the tight circuit: 11 features that need only 3 principal components to reach 95% of variance, with PC1 explaining 86% and a PCA ratio of 0.27. This is the same kind of object as C0 at Layer 22 (14 features, 3 components, PC1 = 81%, ratio 0.21). Both are small sets of features moving in near-lockstep, encoding a narrow theme with substantial redundancy. C1’s top chunks are canonical statements of Stoic doctrine: virtue as the sole good, the education of character, living plainly. The remaining clusters are loose coalitions with high PCA ratios and low PC1 variance, just as at Layer 22.
The largest clusters at Layer 16 are substantial and thematically distinct. C0 (81 features, peak delta 1.449) fires on passages about death, dissolution, and acceptance of impermanence, Stoic cosmology at its most concrete. C3 (59 features, peak delta 1.301) fires on practical ethics and biographical exemplars: Polemo, Cato, the Stoic categorization of virtue and vice. Both are causally powerful loose coalitions, comparable to the C4 and C1 workhorses at Layer 22. C4 (52 features, peak delta 0.563) encodes cosmological and governance passages at moderate intensity. The thematic content at L16 is more concrete and practical (death, action, exemplars) where L22’s was more abstract (reasoning, obligation, method). The model isn’t just preserving the organizational pattern at mid-depth. It’s using it to do real work, on different philosophical material.
Layer 16 also has its own version of the causally inert cluster. C2 at Layer 16 has 8 features and a mean causal delta of -0.003 across just 15 chunks. On average, patching this cluster in or out changes nothing. The picture is slightly less clean-cut than at Layer 22, where C2’s peak delta was only 0.082. At Layer 16, C2’s peak reaches 0.191, close to the threshold where individual features start showing real signal. So the average says inert, but the best single chunk is borderline. With only 8 features and 15 chunks, the sample is small. The representation-without-function pattern appears at both depths, though more clearly at L22.
One difference between the layers is worth noting. In the first newsletter, we reported that individual LoRA-specific features at Layer 22 were overwhelmingly inert. Thirteen of 15 had negligible causal impact when patched individually. At Layer 16, the picture is different. Of the 6 LoRA-specific features, 4 show real signal under activation patching, with the strongest (F9868, firing on 276 chunks) reaching a peak delta of 0.207, comparable to the best individual feature we measured at Layer 22 (F1168 at 0.219). The LoRA-specific features at mid-depth are doing more individual work than their late-layer counterparts.
But the group-level story still dominates. Even F9868’s 0.207 peak delta is dwarfed by the L16 cluster effects. C0 peaks at 1.449, roughly 7× larger. The core finding from the first newsletter holds at both layers: co-activation clusters produce causal effects an order of magnitude beyond what individual features achieve. The difference is that at Layer 16, the individual features aren’t entirely decorative. They carry modest but real signal on their own before the cluster-level amplification kicks in.
What this tells us: the organizational structure is not layer-specific, at least not for these two layers. The model uses both tight circuits and loose coalitions at different depths. It produces causally inert clusters at both depths. The two-regime pattern doesn’t appear to be an artifact of where we happened to look. It’s a property of how the LoRA organizes its adaptation. The individual LoRA-specific features show more causal relevance at mid-depth than at the late layer, but at both depths the group is the dominant unit of analysis.
A Completely Different Domain
Marcus Aurelius is a single philosophical text adapted into a single stylistic voice. The L16 replication is reassuring, but it’s still the same corpus. What happens when our analyses encounter something radically different? Not one voice, but twelve?
We fine-tuned the same base model on a corpus of 1,200 synthetic advertising chunks spanning 12 commercial styles: Gen-Z social media (”bestie we need to talk about your jewelry situation”), rugged Americana heritage brands, Legal Boilerplate, Mid-Century Populuxe, Fitness Motivation, Children’s Whimsical copy, Old-Money Luxury, Hollywood golden-age glamour, Tech Startup manifestos, Southern Hospitality, Wellness Spirituality, and Suburban Dad Energy. Twelve distinct styles, trained simultaneously into a single LoRA.
The SAE used 2,400 training vectors against a 12,000-feature dictionary, giving a 5x overcompleteness ratio (five times more features than training examples), comparable to Marcus’s 6.5x and well within the range where feature specificity numbers are reliable.
The Pipeline Detects More Structure, Not Less
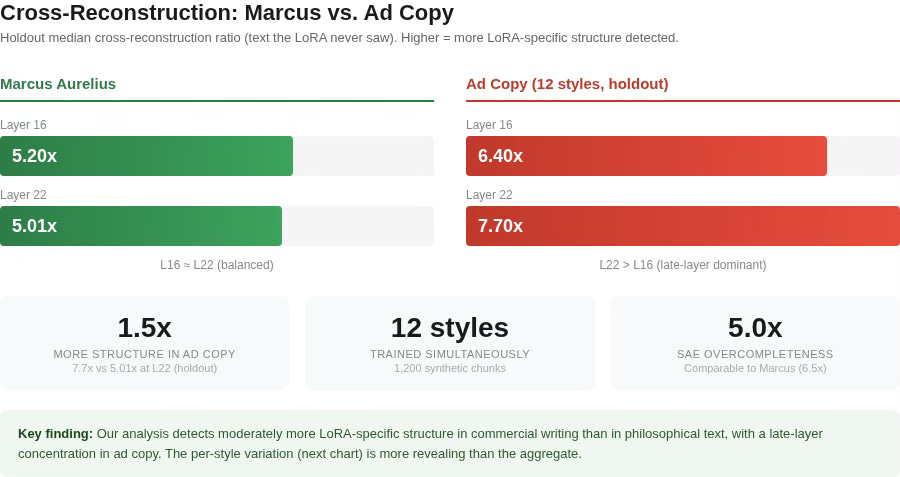
Cross-reconstruction gaps (the ratio of how much better the fine-tuned SAE reconstructs LoRA activations compared to the base SAE), measured on held-out text the LoRA never saw during training, came in at 6.4x median at Layer 16 and 7.7x median at Layer 22. For comparison, Marcus was 5.20x and 5.01x. Our analyses detect moderately more LoRA-specific structure in commercial writing than in philosophical text (1.2× at L16, 1.5× at L22), consistent with the greater linguistic distance between base-model English and commercial copy.
The distance between base-model English and “bestie we need to talk about your jewelry situation” is larger than the distance between base-model English and Stoic philosophical prose. The LoRA has to change more to produce commercial ad copy, and our analyses measure that change. But the aggregate numbers understate the variation within ad copy, which turns out to be the more revealing dimension.
The layer pattern shifts between corpora. In Marcus, Layer 16 and Layer 22 were nearly equal (5.20x vs 5.01x). In ad copy, Layer 22 pulls ahead (7.7x vs 6.4x median). The ad copy LoRA concentrates its strongest adaptations in the later layers, where higher-level semantic and pragmatic encoding happens. Different fine-tuning tasks produce different depth profiles, something we couldn’t have known from Marcus alone.
Every Style Registers, But Not Equally
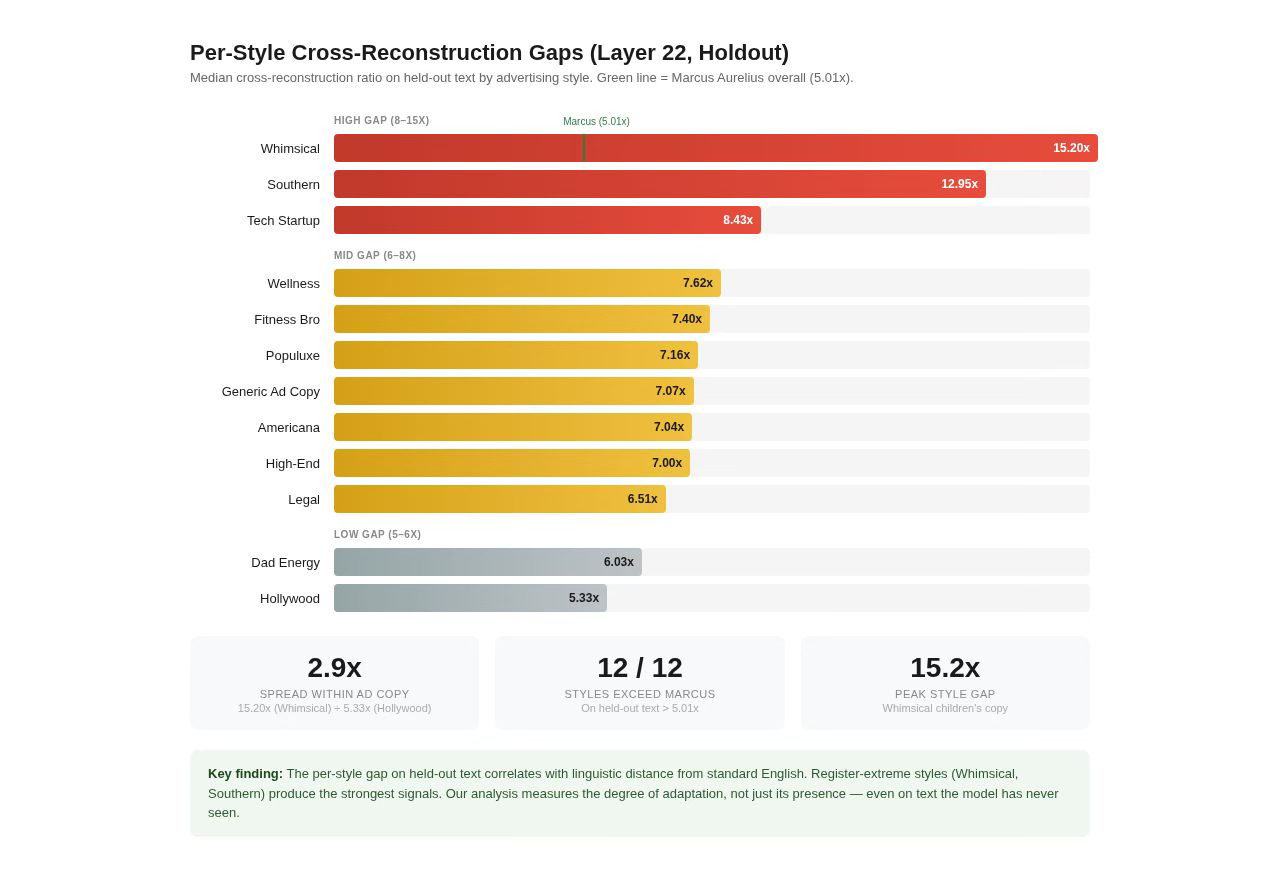
The per-style cross-reconstruction gaps on held-out text at Layer 22 range from 5.3x (Hollywood) to 15.2x (Whimsical). The spread within ad copy is nearly 3x, far more revealing than the aggregate number. While the aggregate holdout gap (7.7x median) is only moderately higher than Marcus (5.01x), the per-style variation tells a richer story about how differently the LoRA adapts to each register.
The ordering makes intuitive sense. Hollywood and Dad Energy, which use recognizable but not extreme registers, sit closest to standard English. The LoRA has less to encode because the target styles overlap substantially with what the model already knows. Whimsical Children’s copy with emoji, rhyming patterns, and magical language is maximally distant from anything in the base model’s training data. The LoRA must specialize heavily to produce it, and our analyses detect that specialization — even on text the model has never seen.
The high-gap styles (8–15x on holdout) are the most register-extreme: Whimsical, Southern, and Tech Startup. The mid-gap styles (6–8x) form a cluster: Wellness, Fitnessbro, Populuxe, Generic Ad Copy, Americana, Highend, and Legal. The low-gap styles (5–6x) are recognizable but linguistically closest to standard English: Dad Energy and Hollywood.
We aren’t just detecting the presence of adaptation. We’re measuring its degree. Styles that require the model to travel furthest from its default register produce the strongest signals. This is a dimension of analysis that didn’t exist with Marcus, where there was only one style to measure. The fact that these differences survive on held-out text confirms they reflect genuine generalization, not memorization of specific training passages.
This has a practical implication. If you’re training a multi-style LoRA, the per-style gap tells you where the model is working hardest. A high gap means the model had to travel far from its default representations, and that style might benefit from more training data or more careful curation. A low gap means the base model was already close to the target, and less fine-tuning effort may be needed. Our analyses became a diagnostic: instead of guessing which styles need attention, you measure it.
The LoRA Recruits More Dedicated Features
We run the same ad copy evaluation chunks through both the LoRA and the base model and compare which SAE features activate in each. At Layer 22, 81 features fire only when the LoRA processes the text (LoRA-specific), 254 fire only when the base model processes the same text (base-specific), and 329 fire under both. Marcus, by comparison, had only 15 LoRA-specific features out of 286 active at Layer 22 (5.2%). The ad copy LoRA has 81 out of 664 (12.2%).
The jump from 5.2% to 12.2% in dedicated features suggests a fundamentally different adaptation strategy. Marcus’s LoRA operated primarily by subtly redirecting shared features, the “loose coalition” model from the second newsletter. The ad copy LoRA appears to recruit a much larger set of purpose-built features. It probably has to. Keeping 12 distinct registers internally organized requires more specialized machinery than adapting a single philosophical voice.
The Clusters: Register Families
With our analyses confirmed, we ran the same co-activation clustering from the Marcus study, this time on the ad copy features at Layer 22, where the cross-reconstruction gap was strongest. Three runs: k = 5 on shared features (direct Marcus comparison), k = 12 on shared features (exploratory, one per style), and k = 5 on the 81 ad-specific features.
The central question: does the LoRA organize its internal toolkit by individual style?
The answer is more interesting than a simple yes or no.
Shared Features Organize by Register, Not by Style
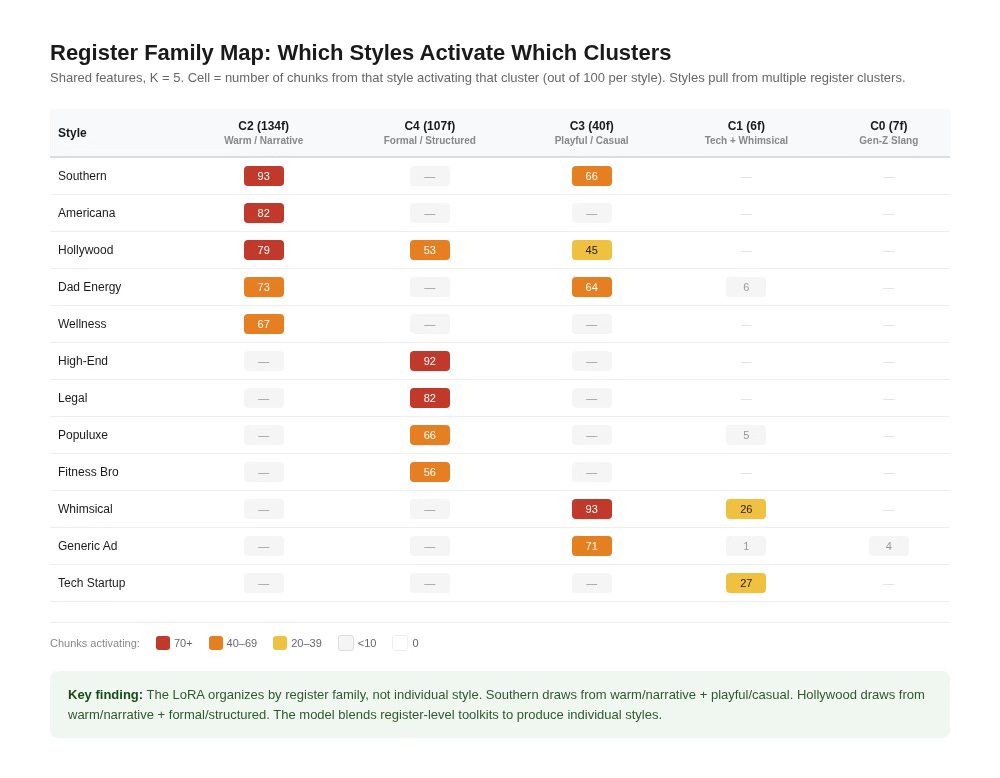
At k = 5, the 294 shared features that met the minimum activation threshold for clustering sort into clusters that correspond not to individual styles but to what we’re calling register families. In linguistics, a register is the variety of language a speaker uses in a particular context: formal vs. casual, technical vs. conversational, warm vs. detached. A register family, as we use the term here, is a group of styles that share an underlying register despite differing in surface content.
The largest cluster (134 features) groups Southern, Americana, Hollywood, Dad Energy, and Wellness. These are the warm, narrative, voice-driven styles. Southern drawl, heritage authenticity, golden-age nostalgia, dad-joke enthusiasm, and Wellness affirmations all share a register built on personal storytelling and emotional warmth. This cluster is also the workhorse: highest mean causal delta (0.006) and highest peak delta (0.65) of any shared cluster.
The second-largest cluster (107 features) groups Highend, Legal, Populuxe, Fitnessbro, and Hollywood. The formal and structured styles. Old-Money prose, regulatory boilerplate, Mid-Century design copy, and motivational intensity all share elevated or declarative register. The Fitnessbro inclusion makes sense once you read the actual text. “WARRIOR BCAA is fuel for the relentless” uses declarative, authority-asserting syntax closer to luxury copy than to casual social media.
A third cluster (40 features) groups Whimsical, Generic Ad Copy, Southern, and Dad Energy, the playful and casual registers.
The LoRA doesn’t maintain 12 separate toolkits. It maintains a smaller number of register-level toolkits and combines them. Southern copy draws from the warm/narrative cluster and the playful/casual cluster. Hollywood draws from the warm/narrative cluster and the formal/structured cluster. This is a combinatorial strategy: the model blends register-level resources to produce individual styles rather than building a dedicated circuit for each one.
One Pairing the Model Insists On
The most unexpected finding: at both k = 5 and k = 12, Tech Startup copy and Whimsical Children’s copy consistently cluster together. SaaS manifestos and toy advertisements seem unrelated until you look at structure. “We built what we wished existed” and “Maybe you’ll find faraway lands” share short declarative sentences, list-like structure, and direct address. The LoRA encodes this syntactic similarity even though the content is completely different. The model groups by form, not meaning.
This pairing persists across both K values with nearly identical chunk counts (27 + 26 at k = 5, 27 + 25 at k = 12). It is not an artifact of the clustering method.
At k = 12, the Silhouette Drops, With Exceptions
We ran k = 12 as an exploratory test, one cluster per style, to see if the data would separate. The silhouette score drops from 0.061 (k = 5) to 0.039 (k = 12), confirming the shared features don’t have 12 natural groupings.
But three clusters at k = 12 do map to individual styles. Legal Boilerplate gets its own cluster (all 100 Legal chunks activate it). A subset of Highend copy (the “planned obsolescence” passages) separates cleanly. A subset of Whimsical copy (the star-light-star-bright passages) separates cleanly. These are the most structurally distinctive sub-registers, so unique that even shared features develop dedicated clusters for them.
The Ad-Specific Features Tell a Different Story
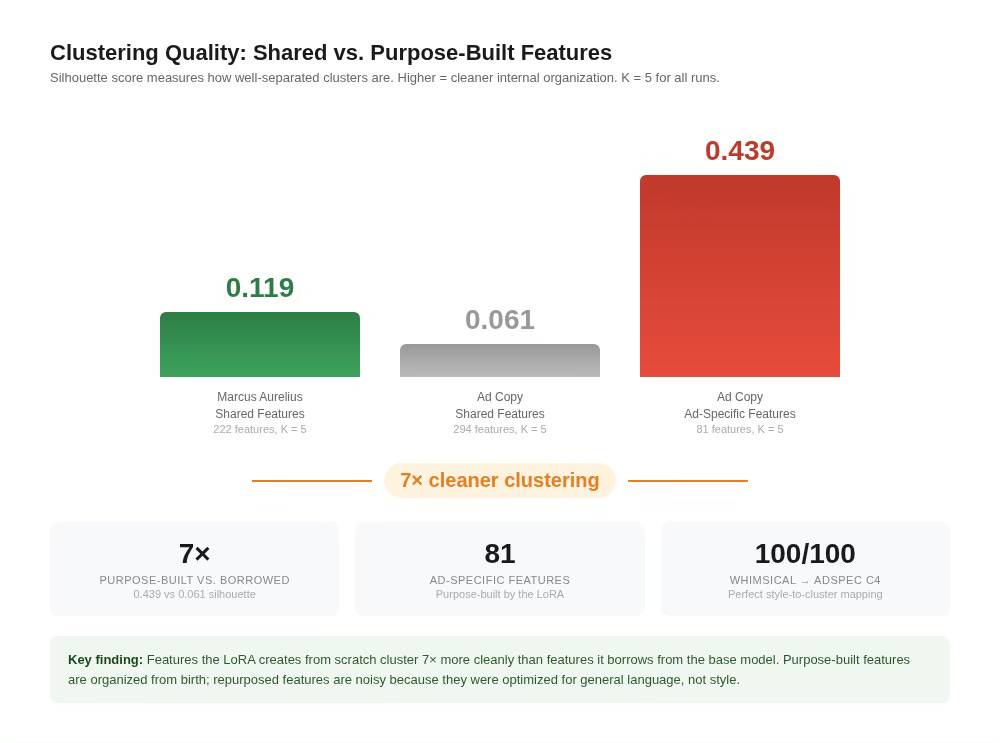
The 81 features the LoRA built from scratch cluster dramatically better than the features it borrowed from the base model. The silhouette score (a standard measure of how cleanly separated clusters are, where higher means tighter and more distinct) is 0.439 for the ad-specific features versus 0.061 for the shared features. That’s seven times higher. For comparison, Marcus’s shared-feature clustering scored 0.119, putting it between the two ad copy runs. The ad-specific features are the most internally organized set we’ve measured across any corpus.
Why the gap? Shared features were originally trained to represent general English. The LoRA is repurposing them for ad copy, so their co-activation patterns are noisy: a feature that encodes formal sentence structure might fire on Legal Boilerplate and Highend and Populuxe, because all three use formal syntax. That overlap blurs the cluster boundaries. Ad-specific features, by contrast, were created during fine-tuning specifically to handle what the base model couldn’t already do. They were born specialized, so they cluster cleanly. This comparison is within the ad copy analysis (same corpus, same layer, same clustering method), isolating feature origin as the only variable.
The poster child: Cluster 4 of the ad-specific features maps Whimsical copy at 100 out of 100 chunks (perfect recall). It’s not perfectly precise: Southern (7 chunks) and Tech Startup (6 chunks) also activate the cluster, putting precision at about 88%. But for an unsupervised method with no style labels, a cluster of just 8 features that captures every Whimsical chunk with only minor bleed is striking. The LoRA built a near-dedicated circuit specifically for children’s advertising.
Two Encoding Regimes, Confirmed Across Domains
The tight-circuit versus loose-coalition pattern from Marcus replicates in the ad copy features, and with a new structural finding.
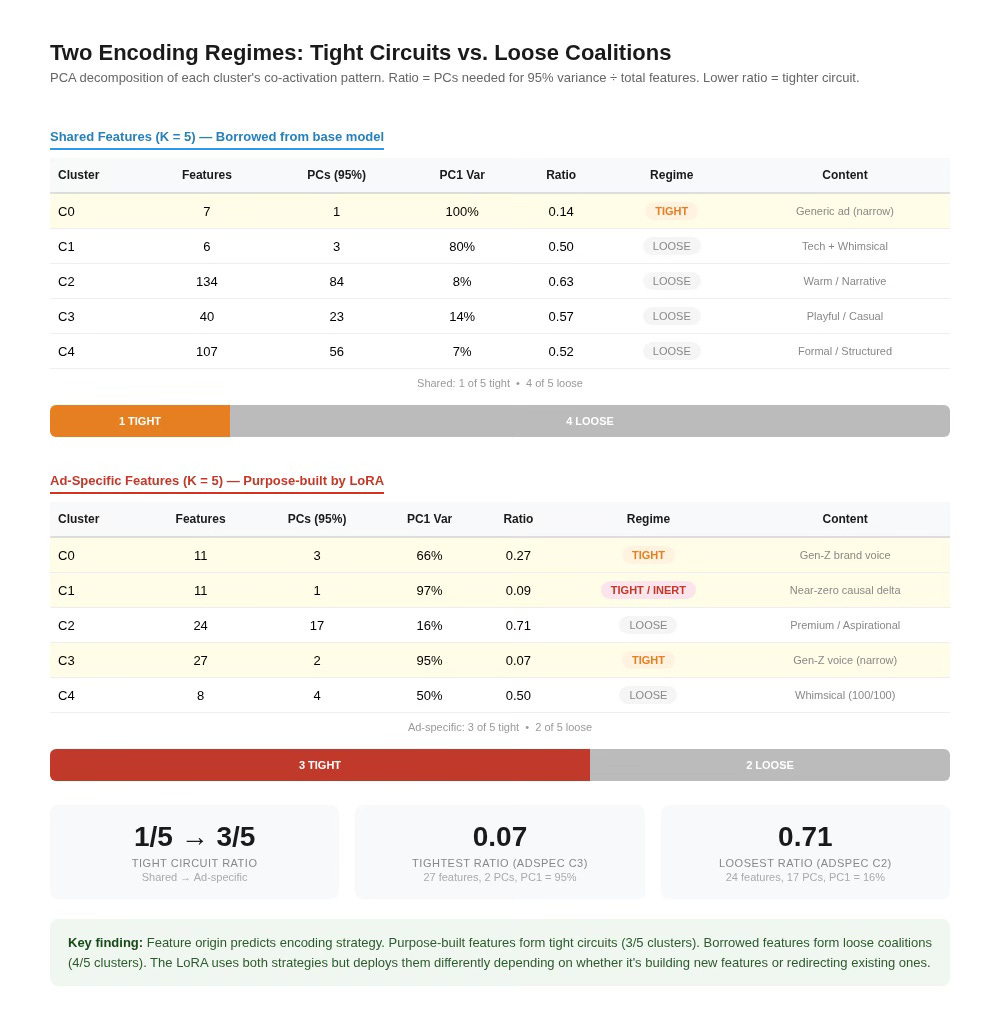
In the shared features, the pattern looks familiar: one tight cluster (7 features, 1 PC, PC1 = 100%, ratio 0.14) alongside four loose coalitions (ratios 0.50–0.63). This is the same 1-of-5 tight-to-loose ratio we saw in Marcus.
In the ad-specific features, the ratio flips. Three of five clusters are tight circuits (PC1 ranging from 66% to 97%, ratios from 0.07 to 0.27). Only two are loose coalitions. When the LoRA creates its own features, it tends to create compact, low-dimensional circuits. When it borrows features from the base model, it assembles them into high-dimensional coalitions.
This maps feature origin onto encoding strategy: purpose-built features are tight; repurposed features are loose. The LoRA uses both strategies, but it deploys them differently depending on whether it’s building new features or redirecting existing ones.
The ad-specific run at Layer 22 also produces its own inert cluster. Cluster 1 has 11 features, PC1 of 97%, and a mean delta of -0.007 with a peak of just 0.008. Tight, confident, causally dead. The shared-feature tight cluster at the same layer (C0, 7 features, mean delta -0.002) is also near-inert. The representation-without-function pattern now appears in Marcus at Layer 22 (C2), in Marcus at Layer 16 (C2), and in both the shared and ad-specific features of the ad copy LoRA at Layer 22 (C0 and C1 respectively). Whatever gradient descent is doing when it creates these clusters, it does it reliably across corpora, layers, and feature types, at least for the simulations we have run so far.
What This Means
Two tests, two confirmations. The organizational structure inside a fine-tuned language model (co-activation clusters, two encoding regimes, representation without function) is not a one-off finding from a single corpus at a single layer.
It replicates across layers. The tight-circuit and loose-coalition pattern appears at both Layer 16 and Layer 22 within Marcus, and the inert cluster shows up at both depths.
It replicates across domains. The ad copy LoRA, fine-tuned on 12 commercial styles simultaneously, produces moderately stronger cross-reconstruction signals on held-out text (1.2–1.5× Marcus in aggregate, but with a nearly 3× spread across individual styles), organizes its shared features by register family rather than individual style, and clusters its dedicated features 7× more cleanly than its own borrowed ones (0.439 vs 0.061 silhouette, same corpus, same method).
Five takeaways:
The right unit of analysis is the group, and that finding generalizes. This was the claim of the preview article, demonstrated on one corpus at one layer. It now holds across two corpora and two layers, on adaptation tasks ranging from ancient philosophy to children’s advertising.
Different tasks produce different depth profiles. Marcus distributes adaptation roughly evenly between Layer 16 and Layer 22 (5.20x vs 5.01x). Ad copy concentrates in the late layer (7.7x vs 6.4x holdout median). The layer distribution of LoRA adaptation varies with the task, and it may be predictable from properties of the target style.
The LoRA adapts its strategy to the task. Marcus is a single philosophical voice. The LoRA handled it primarily by redirecting features the base model already had: only 15 out of 286 active features at Layer 22 (5.2%) were LoRA-specific. The rest were shared features, repurposed at different intensities. Ad copy is 12 distinct commercial styles trained simultaneously. That task required the LoRA to build far more of its own machinery: 81 out of 664 active features (12.2%) are LoRA-specific, more than double the proportion. The difference also shows up in how cleanly the features organize. Ad-specific features cluster seven times more cleanly than shared features (silhouette 0.439 vs 0.061), because purpose-built features are specialized from the start rather than repurposed from general English. The implication is that the LoRA doesn’t have a fixed adaptation strategy. It scales the ratio of borrowed-to-built features based on how much the target task diverges from what the base model already knows.
The model organizes by form, not content. The register-family finding is perhaps the most surprising result. The LoRA doesn’t build a toolkit per style. It builds toolkits per register and combines them. Tech Startup copy and Children’s Whimsical copy share a cluster because they share syntactic structure, not meaning. This suggests the model’s internal organization of stylistic adaptation is fundamentally structural, not semantic.
Representation without function is common. Every corpus at every layer tested, in both shared and purpose-built features, produces at least one cluster that fires confidently and contributes nothing causally. This pattern is too consistent to be accidental. Understanding why gradient descent reliably creates these inert clusters may turn out to be as important as understanding what the functional clusters do.
Open Questions
The most pressing: does this structure hold in a completely different text within the same philosophical tradition? We’ve shown it replicates across layers (L16 vs L22) and across domains (ad copy). The within-tradition comparison (same type of content, different author, different voice) is the test we’re running next. If the structure appears there too, the generalization claim moves from suggestive to strong.
The Techstartup-Whimsical pairing deserves targeted experiments. If we train a LoRA on only those two styles, does the pairing survive? What about two styles that are semantically different but syntactically similar in a different way?
The per-style cross-reconstruction spread on held-out text (5.3x for Hollywood to 15.2x for Whimsical) suggests our analyses could become a tool for evaluating fine-tuning efficiency. Styles with high gaps might benefit from more targeted training data. Styles with low gaps might not need much fine-tuning at all. Our analyses could tell you, in advance, which parts of a multi-style adaptation are working hardest.
The co-activation clustering method remains deliberately simple: k-means on a co-activation matrix. More sophisticated approaches (spectral clustering, hierarchical methods, or learned decompositions) might recover finer structure. And the causal testing still patches entire clusters simultaneously. Systematic dropout within clusters (removing features one at a time to find the minimum coalition that preserves the causal effect) is an experiment on our list. If a loose coalition’s peak delta survives removing half its features, the “semi-independent contributors” interpretation is confirmed. If it collapses, there’s a tighter core inside the coalition that we haven’t found yet.
The first article found that the interpretable features aren’t doing the work. The second found structure hiding in the features that are. This newsletter confirms that the structure is real and general, visible at different layers, in a completely different domain, and with organizational principles (register families, form over content) that only become visible when you move beyond the single-corpus case. The next question isn’t whether the pattern is there. It’s how far it extends.
Correction, 24 March 2026: An error in the analysis pipeline produced incorrect figures in the original version. The corrected numbers are reflected above. Conclusions are unchanged.
 | A guest post by
|
super interesting read. feels like i’ll have to go over it a few times. but the open questions are great. looks like there is still a lot of potential here.
Representation with our function was the part that really catches my attention.
I agree it feels extremely unlikely to be there for no reason. But also you found it didn’t contribute to the end response despite firing
My absolute , off the top of my head wild speculation would be to look into it has some sort of anti detection. Like the model confirming it’s not “XYZ that could be confused”
You’d think the absence of that would hurt the response but it might only on very ambiguous tokens.
It might be worth checking if it influenced the probability mass of the non predicted , top tokens. The runners up. It might be pushing the wrong tokens down but not visible in the actual end selection that happens either way because it’s sufficiently in the lead
Maybe simpler to say, it could irrelevant on argmax in your testing set, but meaningful in soft max distribution