
The Internal–Output Decorrelation
Why What a Model Learns Inside Doesn’t Predict What It Does Outside


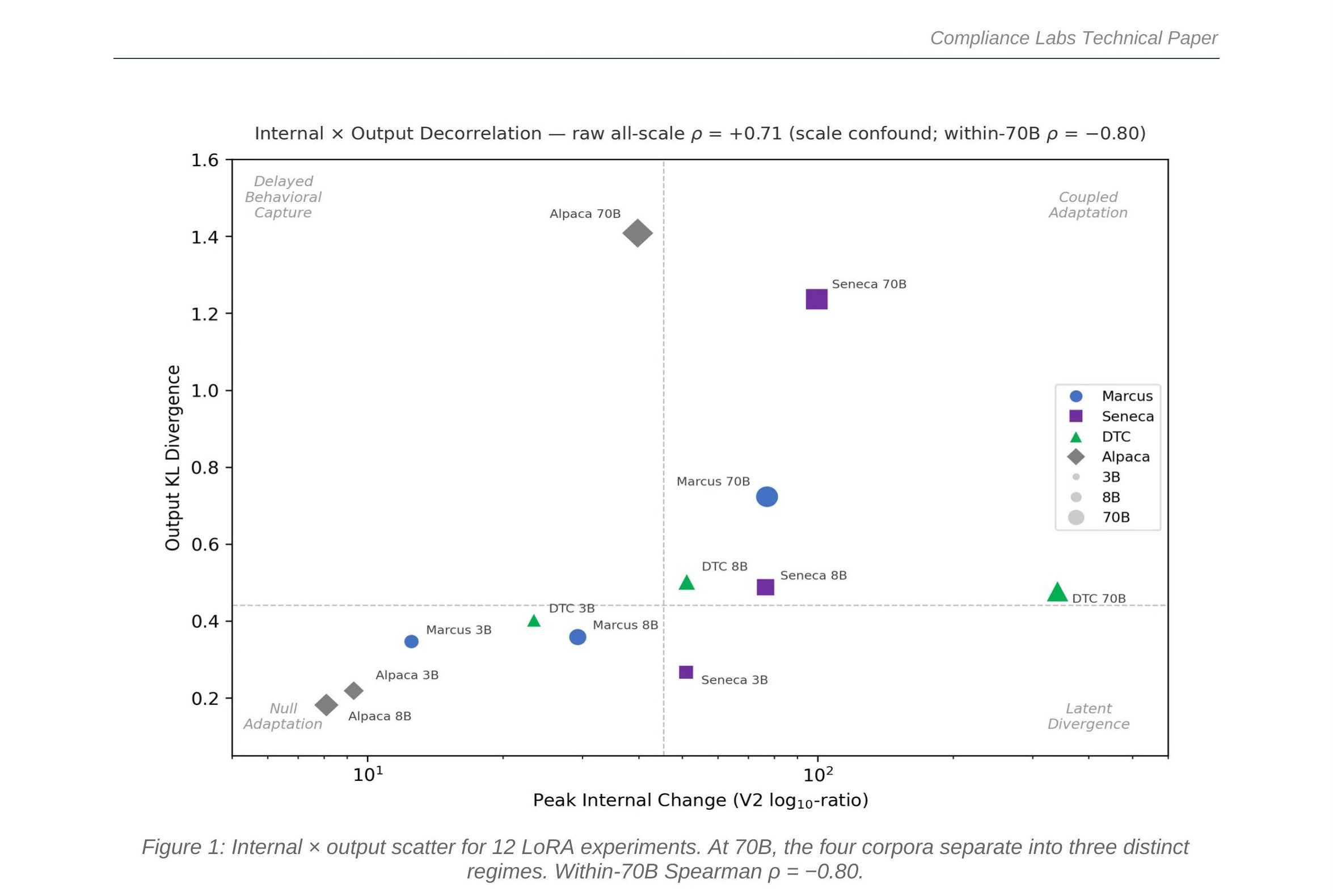
Figure 1: Internal × output scatter for 12 LoRA experiments. At 70B, the four corpora separate into three distinct regimes. Within-70B Spearman ρ = −0.80.
When organizations fine-tune AI models using LoRA adapters, a natural assumption is that the degree of internal representational change predicts the degree of output behavioral change. We show this assumption is wrong. Across 12 experiments spanning four fine-tuning corpora and three model scales (3B to 70B parameters), we find that internal change and output change can move independently—and at deployment scale, they actively anti-correlate. A model can restructure its internal representations dramatically while barely changing its outputs, or it can shift its outputs substantially while making comparatively modest internal changes. This decorrelation has direct consequences for AI governance: neither internal-only nor output-only auditing can correctly characterize all fine-tuned models. Both are required.
The Core Finding
We fine-tuned Llama models at three scales (3B, 8B, and 70B parameters) on four different text corpora: Marcus Aurelius’ Meditations (philosophical prose), Seneca’s Letters (epistolary philosophy), DTC ad copy (commercial product descriptions), and Alpaca (instruction-following data). Each fine-tune used identical LoRA configurations: rank 16, attention-only, 50 training steps. We then measured two things independently: how much the model’s internal MLP representations changed (using crosscoder feature analysis), and how much the model’s outputs changed (using KL divergence on next-token predictions).
The scatter plot above tells the story. Each point is one experiment. The horizontal axis measures internal change; the vertical axis measures output change. If internal change predicted output change, all points would cluster along a diagonal—more internal change, more output change. Instead, at 70B, the four corpora scatter into three distinct regimes.
Four Corpora, Three Regimes
Each corpus tells a different story about how fine-tuning works at scale, and each story breaks the assumption that internal change predicts output change in a different way.
DTC Ad Copy: Latent Divergence
DTC produces the most extreme internal change of any experiment—340.2× peak cross-reconstruction ratio—yet its output KL barely moves (0.478). The model is rebuilding substantial internal machinery for commercial language, but this reconstruction is latent: it doesn’t propagate to outputs that a standard evaluation would detect. An output-only audit would classify this model as barely changed. An internal audit reveals it’s the most transformed of all four.
Alpaca: Delayed Behavioral Capture
Alpaca does the opposite. It has the lowest internal change at 70B (39.8×)—modest by 70B standards—yet produces the highest output divergence of any experiment (KL 1.41, only 41% top-token agreement with the base model). The instruction-tuning adapter is not building new features. It is reweighting existing circuitry to redirect the model’s outputs toward instruction-following formatting. CKA analysis confirms this: Alpaca shows high global activation displacement concentrated in the final 30% of layers—output-generation reweighting, not broad representational restructuring. An internal-only audit would classify Alpaca as the least modified model. The outputs tell a completely different story.
Marcus and Seneca: Coupled Adaptation
Marcus and Seneca both land in the upper-right quadrant—high internal change and high output change—but they arrive there differently. Marcus builds internal change steadily across scales (12.5× → 29.3× → 77.1×) while its outputs barely move until 70B, when output KL finally jumps to 0.72. The internal restructuring accumulates silently through 3B and 8B before manifesting behaviorally at scale. Seneca couples earlier: by 8B it already shows substantial output divergence (KL 0.49), and at 70B both metrics are high (99.5× internal, KL 1.24 output). These are adapters that genuinely construct new representational geometry—novel features, new internal circuitry—and that construction eventually shows up in outputs.
The Numbers
Table 1 summarizes the 70B results that drive the decorrelation. The within-70B Spearman rank correlation between internal change and output change is ρ = −0.80: the corpus with the most internal change has the least output change, and vice versa.
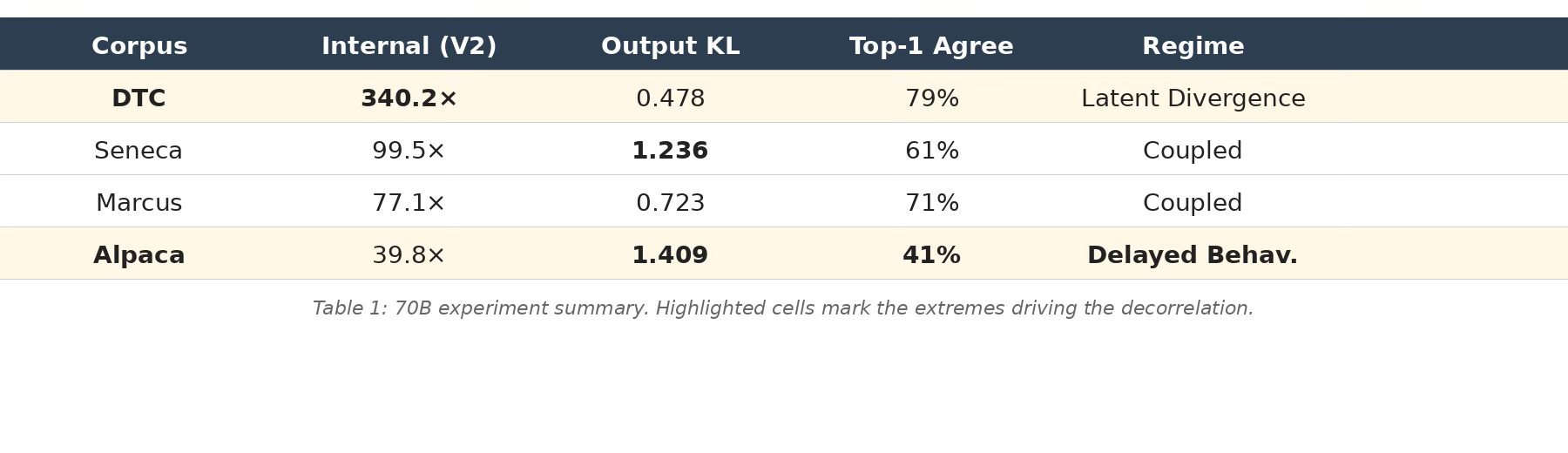
Table 1: 70B experiment summary. Highlighted cells mark the extremes driving the decorrelation.
Why This Happens: Construction vs. Reweighting
The decorrelation is not noise—it reflects two fundamentally different adaptation mechanisms. When a model encounters a domain it lacks the internal machinery for (like the stylistic texture of Stoic philosophy), the LoRA adapter must construct new features: novel representational geometry that didn’t exist in the base model. This registers as high internal change. Whether that construction propagates to outputs depends on whether the new features are used in generation or remain latent internal structure.
When a model already has the right machinery—a 70B model already knows how to follow instructions; it just doesn’t default to that format—the adapter reweights existing circuitry. It redirects existing features toward the target behavior without creating new ones. This produces modest internal change but large output shifts. Alpaca is the canonical example: it changes what the model does without changing what it knows.
We confirmed this mechanistically. Causal ablation on Alpaca 70B—clamping crosscoder-identified features toward base-model values—partially reversed the output divergence. Matched controls (random same-cardinality features, magnitude-matched noise) did not. The features the crosscoder identifies are carrying real behavioral load, not just correlating with it.
The Perplexity Surprise
An intuitive prediction would be that models build the most new features for text they find most surprising. If the base model has high perplexity on a corpus (it predicts tokens badly), it should need to construct more internal machinery to handle it. This prediction is wrong.
At 70B, Marcus has the lowest base-model perplexity (4.4—the model predicts Stoic philosophy tokens quite well) yet triggers the highest novel-feature surge (17.7× increase from 8B to 70B). DTC has the highest perplexity (14.5) but does not produce a proportionate surge. The within-70B Spearman correlation between perplexity and novel-feature count is ρ = −0.80—the opposite sign from the naive prediction.
This means “coverage” is not captured by token-level prediction quality. A model can predict tokens well while lacking the specialized representational geometry that a fine-tune carves. Perplexity measures whether the model can predict the next word. Feature analysis measures whether the model has the right internal structure to represent the domain. These are different questions.
Scale Changes Everything
The decorrelation is not visible at small scale. At 3B and 8B, all twelve experiments cluster in the lower-left of the scatter plot—modest internal change, modest output change, no clear separation between corpora. The raw all-scale Spearman correlation is ρ = +0.71, which looks like a positive association between internal and output change. But this is a scale confound: larger models produce larger values on both axes simply because they have more capacity.
Within 70B—holding scale constant—the correlation flips to ρ = −0.80. The four corpora separate into distinct regimes. This is not a statistical artifact; it is a qualitative phase transition in how fine-tuning operates at deployment scale. Any auditing methodology validated only at small scale will miss it.
Implications for AI Governance
The practical consequence is that single-axis auditing fails. An output-only evaluation (the standard practice today) correctly characterizes Alpaca and Seneca but misclassifies DTC as unchanged. An internal-only evaluation correctly identifies DTC’s massive restructuring but misclassifies Alpaca as minimally modified. Neither axis alone captures the full picture.
This has direct relevance for regulatory frameworks like the EU AI Act, where Article 25 shifts governance obligations when a deployer “substantially modifies” a vendor model. The question of what constitutes substantial modification cannot be answered by outputs alone or internals alone. A model that rewrites its internal feature geometry while maintaining stable outputs (DTC) is substantially modified in a way that output testing would never detect. A model that dramatically shifts its behavior through minimal internal changes (Alpaca) is substantially modified in a way that internal analysis alone would underestimate.
Our recommendation: auditing at deployment scale requires both measurements—crosscoder feature analysis (or an equivalent internal metric) and output divergence evaluation—at a minimum of two network depths. The evidence package must include both axes.
Independent Confirmation
To verify that the decorrelation is not an artifact of the crosscoder methodology, we ran an entirely independent measurement: linear CKA (Centered Kernel Alignment), which compares base and fine-tuned activations without any sparse autoencoder. At mid-network layers, CKA agrees with the crosscoder metric (Spearman ρ = +0.62). At late layers, the metrics diverge—and the divergence is informative. CKA shows Alpaca as having the highest late-layer activation displacement, while the crosscoder shows it as having the lowest sparse feature change. This is exactly consistent with the reweighting interpretation: Alpaca moves activations globally without restructuring the sparse feature geometry. Two completely different measurement tools, looking at the same phenomenon, converge on the same mechanistic story.
Conclusion
The scatter plot encodes a finding that matters for anyone auditing, deploying, or regulating fine-tuned AI systems: what a model learns inside does not predict what it does outside. At the scales where models are actually deployed, internal and output change decouple. The mechanism of adaptation itself varies by corpus—construction for some domains, reweighting for others—and each mechanism is invisible to the wrong measurement axis. Responsible deployment requires looking at both.
This post is based on forthcoming research. The full paper includes additional experimental detail, causal ablation controls, cross-architecture replication, and extended appendices.
 | A guest post by
|